

Predicting Hospital Stay Duration for Efficient Healthcare Management
Improving patient care and resource allocation by predicting hospital stay duration.
1Overview & Strategic Importance

Problem Statement
Predicting hospital length of stay is crucial for efficient resource allocation, patient care planning, and cost management in healthcare facilities. Various patient attributes, including medical conditions, laboratory test results, and vital signs, influence the duration of a patient’s hospital stay.
Traditional methods of estimating hospital stays rely on historical data and manual assessments, which may not fully capture the complexity of patient conditions. A predictive model capable of estimating hospital stay duration based on patient demographics and clinical features can help optimize hospital operations, reduce overcrowding, and enhance patient care efficiency.
Required Solutions
- Analyzing historical admission data to identify key factors affecting stay duration.
- Developing a predictive model based on demographics, diagnoses, and medical test results.
- Providing an efficient and scalable solution for optimizing hospital resource planning.
- Supporting healthcare providers in improving patient flow and reducing hospital congestion.
Solution Objectives
- Perform exploratory data analysis to understand the relationship between patient attributes and hospital stay duration.
- Develop a regression-based model to predict hospital length of stay based on clinical and demographic data.
- Evaluate model performance to ensure accurate forecasting of hospital stay duration.
- Provide insights that can assist hospital administrators, healthcare providers, and policymakers in optimizing patient care and hospital resource allocation.
Understanding the Problem
Hospital length of stay is influenced by multiple factors, including the patient’s medical history, laboratory test results, and severity of illness. Accurately estimating the length of stay can help healthcare providers improve treatment planning and hospital capacity management.
Machine learning models can assist in predicting hospital stay duration by identifying patterns in patient data. While predictive models provide valuable insights for hospital operations, they should be used alongside clinical expertise and real-time patient monitoring to enhance decision-making.
2About the Data
Data Collection
This dataset has 100k data points on patients admitted into hospital, indicators of their health condition and how long they were admitted in the hospital. It been taken from this website which contains the full data description: https://microsoft.github.io/r-server-hospital-length-of-stay/input_data.html
Major Parameters Description
Download Training DataeidA unique patient identifier used for tracking hospital admissions.
vdateThe visit date, representing when the patient was admitted to the hospital.
rcountThe number of times the patient has been admitted to the hospital.
genderThe gender of the patient (M for male, F for female).
dialysisrenalendstageIndicates whether the patient has end-stage renal disease requiring dialysis (1 for yes, 0 for no).
asthmaIndicates whether the patient has been diagnosed with asthma (1 for yes, 0 for no).
irondefIndicates whether the patient has iron deficiency (1 for yes, 0 for no).
pneumIndicates whether the patient has pneumonia (1 for yes, 0 for no).
substancedependenceIndicates whether the patient has a history of substance dependence (1 for yes, 0 for no).
3Using iDareAI
Guided Mode Initialization
AUploading Dataset
Click on the **'Upload CSV or Excel Data'** button → Select a source for the dataset → Upload `hospital_stay_train.xlsx` by clicking **'Apply'**. The system automatically analyzes the file, converts it into feature data, and identifies prediction targets.

The system automatically analyzes the uploaded file, converting it into feature data. It then extracts the most likely descriptions of the columns and identifies the top three value-adding targets for prediction. Additionally, the system highlights the economic, social, and environmental impacts of predicting each target.
BChoosing Analysis Mode
Note: In autonomous model building mode, the training process begins by asking a question in the chat box related to the problem you want to solve, such as:
- Which factors impact the length of stay for a patient at a hospital?
- How does the length of a patient's stay influence the hospital's revenue?
The autonomous system processes the query, analyzes the data, and automatically generates a model along with a detailed response that includes insights, predictions, model usability and actionable recommendations. This mode is ideal for users who want quick results without requiring technical expertise or step-by-step involvement. In contrast, manual building mode provides full control over the model-building process, allowing users to select features, configure training settings, choose algorithms, and validate results step-by-step. Manual mode is better suited for users with technical knowledge or those who want to experiment with different model configurations for deeper insights and customization.
Operation Using Autonomous Guided Mode
For autonomous mode, a query was posed and the button clicked to send it for analysis. The system automatically performed the predictive analysis by itself, returned the query response, and finally built an automated AI application on-demand run by deploying the models.
AQuery: “Which factors impact the length of stay for a patient at a hospital?”
BQuery Response
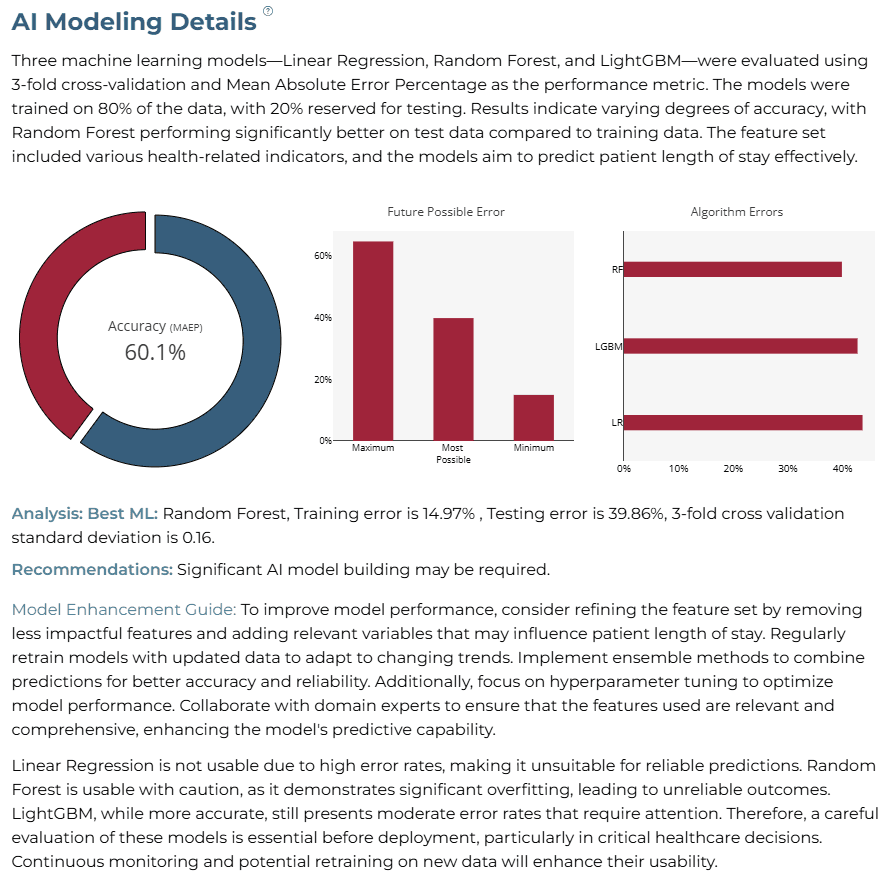
The factors impacting the length of stay for a patient at a hospital include various health conditions and demographic characteristics. Key predictors identified through the analysis include 'dialysisrenalendstage', 'asthma', and 'psychologicaldisordermajor', all of which significantly influence the duration of hospitalization. For instance, patients with end-stage renal disease requiring dialysis tend to have longer stays, while those with asthma and psychological disorders also contribute to increased lengths of stay. Understanding these factors allows healthcare providers to anticipate patient needs and optimize resource allocation effectively. The analysis involved machine learning training, validation, and prediction steps to derive insights into the length of stay. With predictions yielding results of approximately 4.02 days for Linear Regression, 2.06 days for Random Forest, and 4.29 days for LightGBM, it is evident that the majority of patients can expect a stay ranging from around 2 to 4 days, influenced primarily by their health conditions. The AI application built from this analysis allows users to perform new predictions and explore various scenarios by adjusting predictor values, ensuring that healthcare professionals can make informed decisions based on patient-specific factors.
The usability evaluation of the algorithms shows that Linear Regression and LightGBM have high error rates, making them less reliable for practical use in predicting hospital stay lengths. Random Forest, with a test error of 39.86%, is categorized as usable with caution, as it shows some potential but still requires careful consideration before application. The high error rates in the other models suggest they may not provide dependable predictions, emphasizing the need for further refinement and validation before being used in real-world scenarios. It is recommended to focus on improving the Random Forest model and consider additional data for better accuracy.
CAI Application
In automated mode, running the query solves the problem for you step by step and generates the AI application. Users can choose between multiple models for generating predictions. The interface includes sliders that allow users to adjust key variables and see how changes impact the predicted outcome. This dynamic system lets users test different scenarios and explore insights without requiring technical knowledge. The interface also features options to run analyses and review past results, making it user-friendly and accessible for decision-making across various contexts. For more information on AI Application building see here.

Model Fine-Tuning/Manual Model Building
Although the autonomous guided mode provides a full application, the model-building process is open for users to fine tune the solution. Users can scroll up and visit feature selection, group-wise modelling, training performance mode, and training algorithms.
Manual model building allows users to take full control of the model creation process by guiding them step-by-step through data preparation, feature selection, algorithm configuration, model training, and validation. Unlike the automated mode, this approach allows users to customize each aspect of the model based on their understanding of the data and objectives. Following a structured process, users can build customized models that address their needs while maintaining transparency and interpretability.
ASelecting Prediction Target
Analyzing the automated response to the query generated from the problem statement, the 'lengthofstay' column was selected as the target.

BSelecting Analysis Type
The analysis target is a numerical column. So, 'Regression' is selected as the analysis type.

CSelecting Model Group/Item
The group-wise models divide the dataset into subsets to train separate ML models for each unique group or item value. No item/group is required for this dataset.

DSelecting Features
The interface allows you to customize the features used in the predictive analysis by selecting or deselecting any number of variables from the provided list. While the system has automatically recommended up to 10 features based on the selected target and solution type, you are not restricted to these. Using your domain knowledge, you can choose the most relevant features by checking or unchecking them, tailoring the model to better align with the problem you are solving. This flexibility ensures that you can refine the analysis to suit your specific needs and priorities. If any 'datetime' type column is detected, the system automatically detects it.

Select the following features:
- rcount
- psychologicaldisordermajor
- malnutrition
- hemo
- hematocrit
- neutrophils
- glucose
- bloodureanitro
- creatinine
- respiration
- facid
- sodium
- pulse
- dialysisrenalendstage
- substancedependence
- depress
- intercept
ESelecting Training Level
The "Moderate" training level with Moderate performance was selected for this example. Two algorithms are selected for this level: Decision Tree, and Xtreme Gradient Boosting. Rigorous evaluation is conducted using 5-fold cross-validation technique, ensuring the best performance.

FTraining
Training is conducted step by step, starting with the Slow training level. Since this dataset did not perform well in the "Fast" level, the "Moderate" level was opted for. Ultimately the best result was obtained in this configuration.
AI Modeling Details
The model utilizes Xtreme Gradient Boosting and Linear Regression to predict patient length of stay based on various medical features. By analyzing historical hospital data, the model identifies key factors that influence the duration of hospitalization. The model was evaluated using five-fold cross-validation, achieving an accuracy of 88.2%. However, while the overall performance is strong, some prediction errors exist, with a testing error of 11.79%.
While the model provides valuable insights into hospital stay predictions, it may not always be fully accurate due to variations in patient conditions, hospital procedures, and external medical factors. To improve reliability, additional features such as real-time patient vitals, treatment progress, and medical history could be incorporated. Regular retraining with updated hospital records is also recommended to enhance predictive performance and adaptability to evolving medical trends.
This model serves as an analytical tool for hospital management and healthcare planning by assisting in patient flow optimization and resource allocation. However, users should exercise caution when applying predictions in critical medical decisions. Continuous refinements, feature enhancements, and integration with real-time patient monitoring systems could further improve accuracy and practical usability in healthcare settings.
Training Analysis Details
APredicted Target
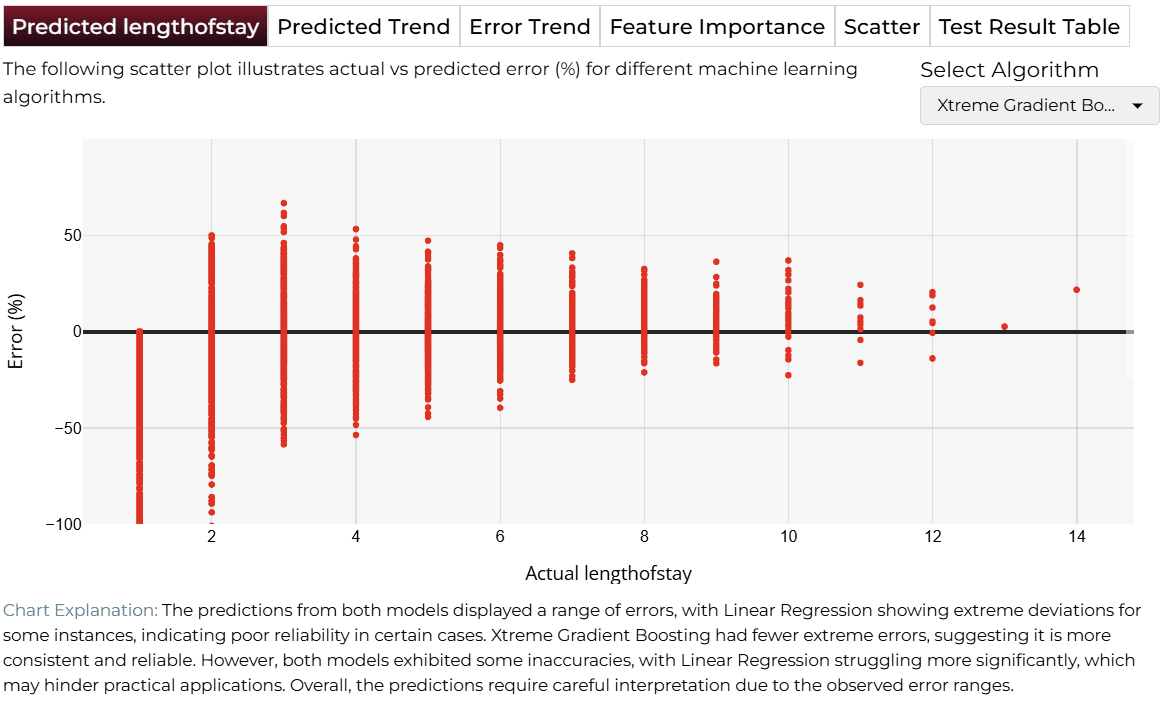
The first tab displays a scatter plot comparing actual vs. predicted patient length of stay errors. The visualization highlights how well the model captures variations in hospital stays. While Xtreme Gradient Boosting exhibits minimal errors and aligns closely with actual values, the Linear Regression model shows more substantial deviations, particularly struggling with extreme cases.
BPredicted Trend
This section illustrates the predicted trend in patient length of stay compared to actual values. The results show that Xtreme Gradient Boosting aligns closely with real-world hospital stays, effectively capturing variations in patient data. Meanwhile, the Linear Regression model struggles with larger discrepancies, suggesting that Xtreme Gradient Boosting is better suited for forecasting patient stay durations.

CError Trend
The "Error Trend" graph tracks model performance across multiple training iterations, focusing on the Mean Absolute Error Percentage (MAEP). The results indicate that Xtreme Gradient Boosting achieves a lower MAEP (11.79%) compared to Linear Regression, which has a significantly higher error rate. This suggests that Xtreme Gradient Boosting provides more stable predictions across different patient records.

DFeature Importance
The "Feature Importance" section highlights the most influential factors in predicting patient length of stay. The analysis shows that 'rcount' and 'neutrophils' were crucial for Linear Regression, while 'bloodureanitro' and 'facid' held more weight in Xtreme Gradient Boosting. Features with low importance, like 'psychologicaldisordermajor' and 'malnutrition,' could potentially be removed to simplify the model without sacrificing predictive power. Adding more relevant features related to patient health could enhance model performance.

Finalize Models
Once you are satisifed with the performance of your selected ML model(s), click on the 'Deploy' button. In this case, the system will save the selected and trained model(s) and deploy them for future demand analysis or batch predictions for production environment.

4AI APPLICATION
Manual Model Building
In the Manual Training Mode, the query response dynamically adjusts based on the values selected in the AI Application interface. Users can manually modify sliders or select specific patient health indicators (e.g., 'rcount', 'neutrophils', 'substance dependence', and 'depress') to configure the inputs. By clicking ‘Get Response,’ the system provides a tailored hospital length of stay prediction that directly corresponds to the selected feature values.
For instance, if sliders for "rcount" and "neutrophils" are adjusted, the query response will focus on their impact on the predicted length of stay. The analysis dynamically updates to ensure the response aligns with the customized inputs, allowing users to explore how variations in medical conditions influence hospitalization duration. This mode offers users greater control and deeper insight into how patient health factors impact length of stay predictions, helping refine resource planning and hospital management strategies.

AI Application Demo
The AI Application is built based on a trained model that predicts the length of hospital stay for patients based on various health indicators. Users can adjust key input variables such as 'rcount', 'neutrophils', 'substance dependence', and 'depress' to explore how changes in these medical factors impact hospitalization duration predictions.
Users can manually adjust the sliders for the following variables. Modify the values to see how different health conditions and patient attributes influence the expected length of stay.
After setting the desired values, click the "Get Response" button. The system will process the input and provide a predicted hospital stay duration based on historical patient data and selected medical parameters.
Saving the Project
The interface allows you to save the AI analysis. For this purpose, you have to save your project by clicking on the icon at the bottom left corner of the textbox (see figure).

Sharing the Project
The system also allows sharing the application for single on-demand predictions accessible to anyone once the analysis is saved.

Interested in similar AI solutions?
Explore our full suite of AI capabilities designed to transform your business operations.